
Article

Coming from a software testing background, I am a big supporter of testing. There are numerous testing techniques from unit, integration, testing in production, manual, automated, etc, but unit testing is the first line of defence against defects or regression.
A good unit test covers a small piece of code, runs quickly, and provides clear feedback to a developer. They have low resource demands and fit into local and CI workflows. These characteristics make them ideal to be run frequently and flexibly, allowing issues to be discovered and resolved early in the development cycle.
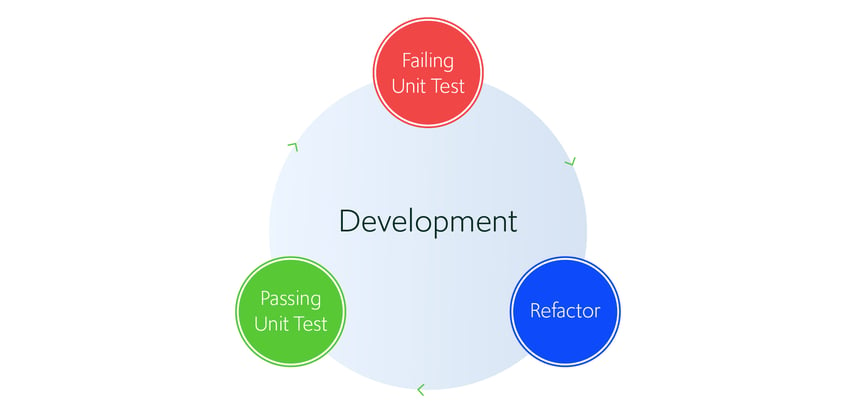
Figure 1: Development feedback cycle
I have been involved in a project that relies heavily on PySpark to create an extract, transform load (ETL) jobs that process huge amounts of data.
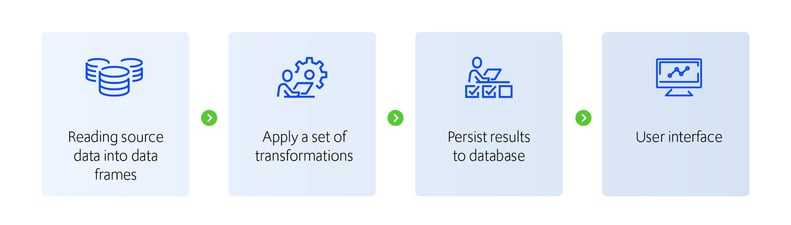
Figure 2: PySpark ETL Job
Once the code is written, the question remains – how do we unit test it?
I am going to take you on the journey, illustrating how I approached unit testing in PySpark with some of these ETL jobs, revealing the challenges and learnings along the way.
Challenge #1 Getting Started
Given our deadlines, we had to strike a balance between delivery and the scope of testing. The team focussed on:
- Defining the critical portions of code
- Deciding to test implementation or behaviour
From that, we concluded that we are not interested in testing implementation details. Instead, we are interested in testing the code’s behaviour – does the unit do the right thing? This would give us focus when testing, ensuring we are efficient and meaningful with our assertions.
Challenge #2 Testable code
Going back to basics, a unit test typically tests a single class, method or function in isolation – so what/who defines the unit boundary?
Let’s look at some code to bring this question to life:
-Jun-22-2021-08-04-00-11-AM.png?width=563&name=image%20(4)-Jun-22-2021-08-04-00-11-AM.png)
As I was new to PySpark, I wrote my entire job within one function – a single unit!
Testing this code would be almost impossible due to numerous reasons, including high coupling, shared state and dependency on external components.
The answer was to break the code into units. The units are many smaller functions that be tested independently. This led me to adopt aspects of the functional programming paradigm:
- Functions must be pure and deterministic: given the same inputs they return the same outputs;
- Functions should not have side effects where possible;
- Where functions do have side-effects, minimise the code in that function;
- Avoid shared state
A better code structure looks like this:.png?width=535&name=image%20(3).png)
Challenge #3 Test Ethos and Data Management
Here, we asked questions around our test ethos:
- Are we using production or synthetic data as our input test data?
We decided on synthetic data for three reasons; we can define data to exercise specifics of our test, security concerns and readability.
- Do we need to construct ‘production-like’ dataframes or can we just supply the columns required for the test?
We decided against creating production-like dataframes. If the function on test only used 3 columns in a 20-column dataset, the other 17 columns just added complexity and made it difficult to reveal what was on test.
- Should we keep data in files or in our code?
We decided on keeping data in code rather than files. Test data in code provided readability and relevance, whilst be curated for the specific test. For small datasets, the apparent simplicity of a file-based approach is quickly outweighed by the benefits of locally defined test data.
- Should test data be shared across tests?
We found that defining data for each test was most effective. Sharing datasets added a significant amount of effort to test data management. Tests that share data often needed to include filtering logic, complicating the test.
This, in addition to adopting the “Arrange, Act, Assert” pattern, enhances the readability and understanding of what each test does.
All four of these points are closely related and are centred around our testing ethos. What do we think is important to us in our scenario; complexity, readability, repetition, exercising code paths/functionality, completeness etc. The balance of these factors helped us to align our thinking across all four questions.
I believe that with the above decisions we met the following properties of good unit tests:
- Easy to write
- Fast to run
- Readable
The journey is not complete yet!
These are some of the next steps I am considering:
- Transition to TDD to avoid as much as possible refactoring code to make it testable
- Promote code reusability via fixtures & libraries
Now go and write some tests!
This article is also featured in Retail Insight's Medium publication.
Written by Tarek Alsaleh
Tarek is a Data Engineer at Retail Insight with an extensive background in software testing, hence approaches problems with a quality-first mindset. Passionate about all things data and focused on building data-intensive applications and tackling challenging architectural and scalability problems.
You might be interested in

Digitizing in-store execution with cognitive technology

Actionable insights and agility enable profitable retail execution

How can retailers optimize their space and assortments post-COVID-19?

One shoe doesn’t fit all – embracing collaborative product design

Real intelligence – Blend the human and machine for business advantage

Chicken Wings at Wingmans

Data-driven performance improvements: Distance running and data

Retail Markdown Optimization: Split Packs & Damaged Items

Using decision science to predict fair retail shrink targets

To realize value from retail analytics, context is critical
